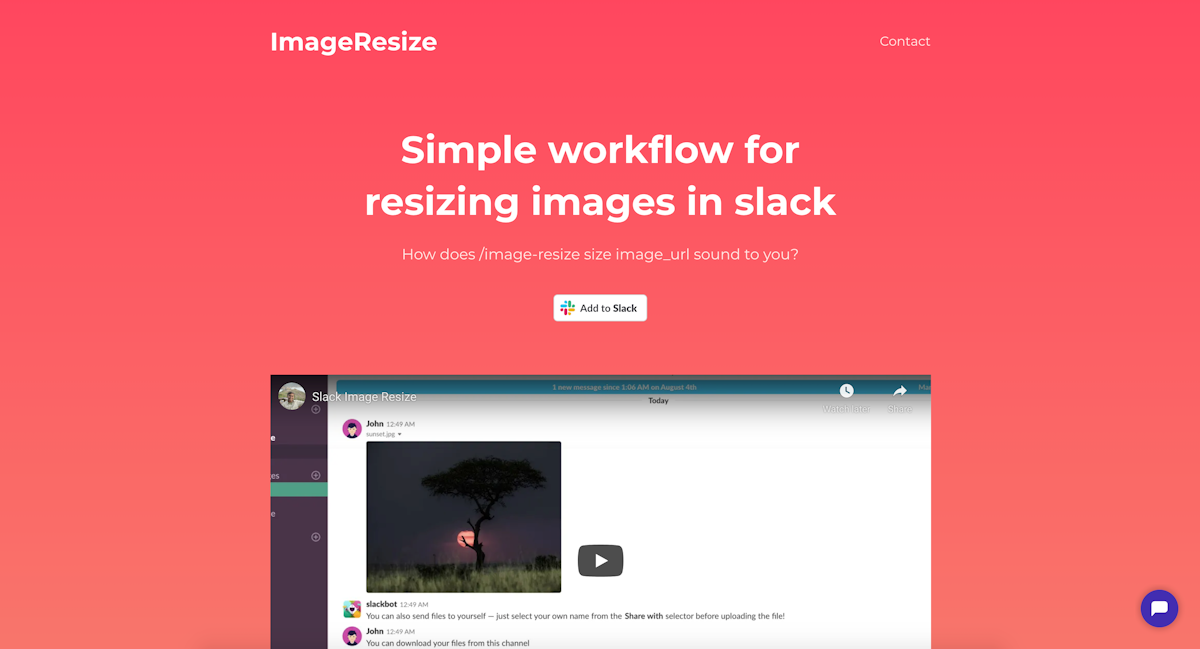
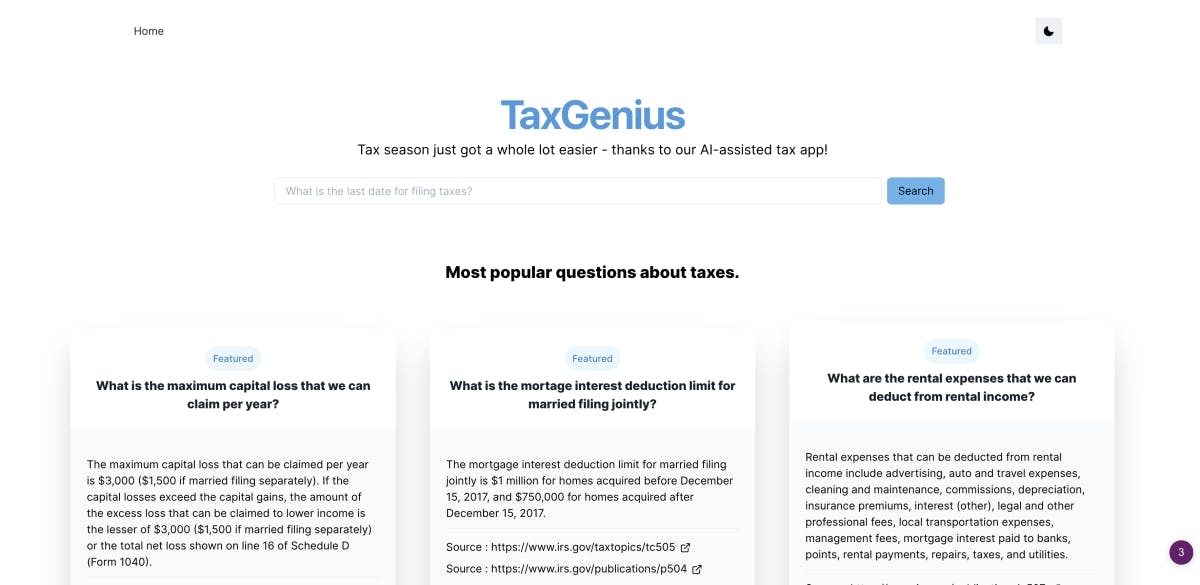
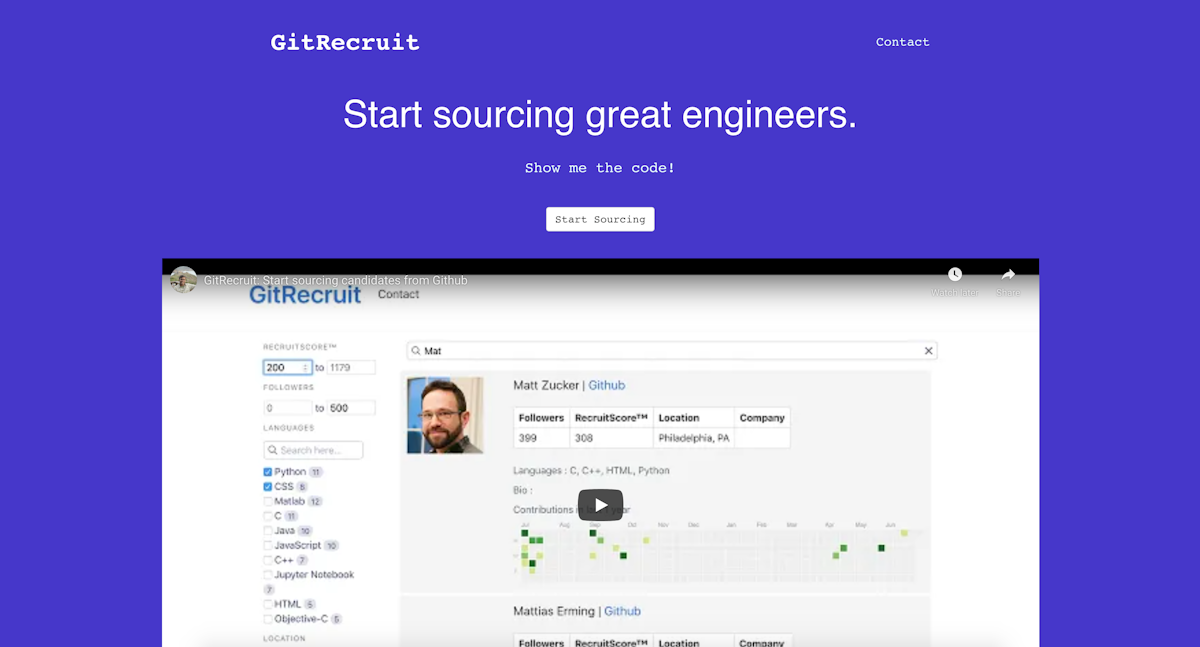
Hey, I’m Shrikar Archak
I’m a Machine Learning engineer by the day and IndieHacker by night/weekend. I am an avid learner who loves to dabble with a lot of technologies and would love to share what I have learnt along the way.
Building side projects and working on problems is something I have been passionate about my whole life. And Currently I am focusing on building audience, how to bootstrap side projects which are beyond hobby projects. Most of the content on the blog going forward will be about this topic and if you like to follow along my journey don't forget to subscribe or follow me on Twitter.
At this point in time I am working on the following goals:
- Learn more about the ChatGPT/LLM's
- Build audience with at least 5k subscribers
- Learn SEO and scale this blog to 20k views per month
- Being productive and proficient in using LangChain/LlamaIndex
With the above goals in mind going forward the blog will focus mainly on ChatGPT, Large Langauge Models (LLM's), Machine learning, Data Pipelines, SEO and IndieHacking.